Naïve Bayesian Classifier | Get Help In Naive Bayesian Classifier | Realcode4you
- realcode4you
- Aug 23, 2025
- 4 min read

Data-driven, not model-driven.
Makes no assumptions about the data.
Named after mid-16th century English statistician and minister Thomas Bayes.
Basics
Find all the other records with the same predictor profile (i.e., where the predictor values are the same).
Determine what classes the records belong to, and which class is most prevalent.
Assign that class to the new record.
One of the simplest and most effective classification algorithms:
Probabilistic classifier: predicts based on the probability of an object belonging to a particular class.
Assumes that features are independent of each other, which is often not the case in real world scenarios.
Despite this, Naïve Bayes performs well in many practical applications.
Basics-Bayesian Classifier
Usage
Requires categorical variables/predictors.
Numerical variable: binned and converted to categorical.
Can be used with very large data sets.
Example: Spell check programs assign your misspelled word to an established “class” (i.e., correctly spelled word).
• Spam filtering, credit scoring, sentiment analysis.
Steps
• Naïve: if the fruit is identified on the bases of color, shape, and taste:
• Red, spherical, and sweet fruit is recognized as an apple.
• Each feature individually contributes to identify that it is an apple without depending on each other.
• Tweak the method so that it answers the question: “What is the propensity of belonging to the class of interest?” instead of “Which class is the most probable?”
• Obtaining class probabilities allows us using a sliding cutoff to classify a record as
belonging to class Ci, even if Ci is not the most probable class for that record.
• Useful when there is a specific class of interest that we are interested in
identifying.
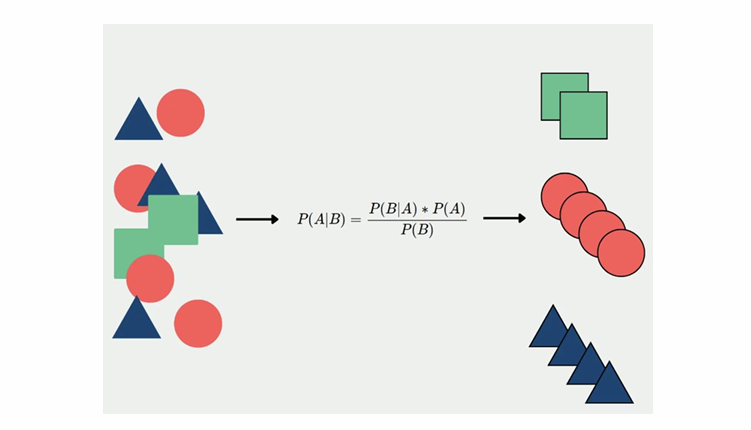
Conditional probability

• To classify a record: compute its probability of belonging to each of the classes in this way, then classify the record to the class that has the highest probability
• Or use the cutoff probability to decide whether it should be assigned to the class of interest).
Example 1

• We assume that no pair of features are dependent.
• For example, the color being ‘Red’ has nothing to do with the Type or the Origin
of the car. Hence, the features are assumed to be independent.
• Also, each feature is given the same influence(or importance).
• Knowing Color and Type alone can’t be used to predict the outcome perfectly.
• None of the attributes are irrelevant and assumed to be contributing equally to
the outcome.

Example 2: Predicting Fraudulent Financial Reporting
Accounting firm: each customer submits an annual financial report to the firm for auditing.
Outcome: “fraudulent” or “truthful”
The accounting firm has a strong incentive to be accurate in identifying fraudulent reports—if it passes a fraudulent report as truthful, it would be in legal trouble.
In addition to all the financial records, it also has information on whether or not the customer has had prior legal trouble (criminal or civil charges of any nature filed against it).
The accounting firm is wondering whether it could be used in the future to identify reports that merit more intensive review.



Exact Bayesian Classifier: shortcomings
Finding all the records in the sample that are exactly like the new record to be classified (i.e. all the predictor values are identical).
When the number of predictors gets larger, many of the records to be classified will be without exact matches.
Example: a model to predict voting on the basis of demographic variables.
• Even a sizable sample may not contain a single match for a new record who
is a male Hispanic with high income from the US Midwest who voted in the
last election, did not vote in the prior election, has three daughters and one
son, and is divorced (just eight variables).

Naïve Bayes

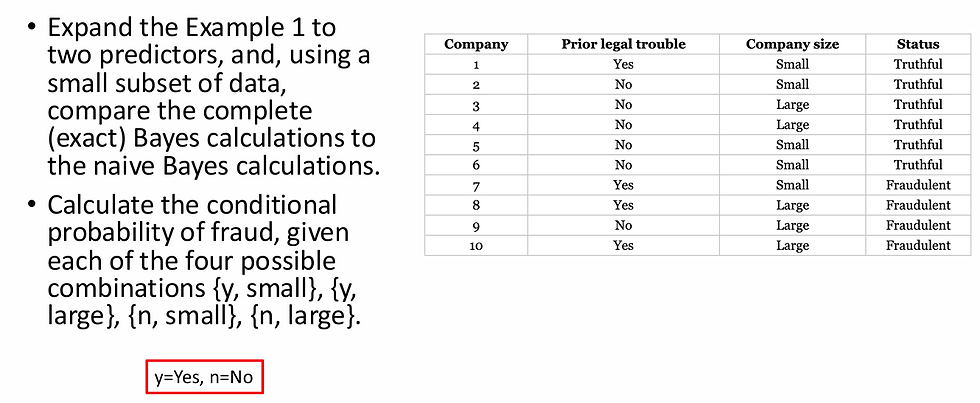
Example 3: Predicting Fraudulent Financial Reports, Two Predictors
Complete Bayes


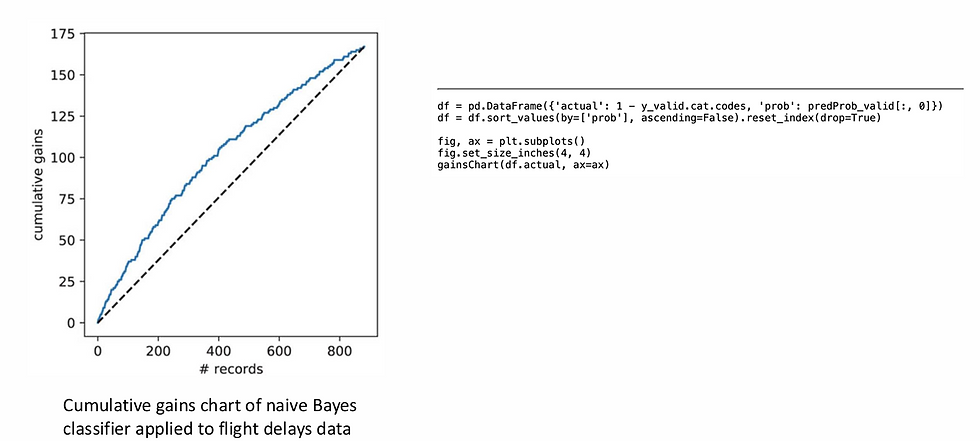
Example 4: Predicting Delayed Flights


Code for running Naive Bayes

Evaluate the overall performance

Strengths of Naïve-Bayes
Simplicity, computational efficiency, good classification performance, and ability to handle categorical variables directly.
In fact, it often outperforms more sophisticated classifiers even when the underlying assumption of independent predictors is far from true.
This advantage is especially pronounced when the number of predictors is very large.
Case Study – Spam Filtering

For each such word, the probabilities are calculated and the formula is applied to determine the naive Bayes probability of belonging to either of the classes.
Class membership (spam or not spam) is determined by the probabilities.
Spammers have found ways to “poison” the vocabulary-based Bayesian approach, by including sequences of randomly selected irrelevant words.
Since these words are randomly selected, they are unlikely to be systematically more prevalent in spam than in non-spam.
For this reason, sophisticated spam classifiers also include variables based on elements other than vocabulary:
• Number of links in the message,
• Vocabulary in the subject line,
• Determination of whether the “From:” e-mail address is the real originator
(antispoofing),
• Use of HTML and images, etc.
For more details you can contact us at:



Comments