Sentiment Analysis & Emotion Recognition | Realcode4you
- realcode4you
- Jan 24, 2024
- 12 min read

SENTIMENT ANALYSIS AND EMOTION RECOGNITION FOR SOCAIL MEDIA
Q) Motivation: why the proposed project is important?
Insight into Public Opinion: Social media platforms have become a vital medium for individuals to express their opinions, emotions, and sentiments. Analyzing these expressions can provide valuable insights into public opinion, preferences, and trends.
Business Intelligence: Organizations can leverage sentiment analysis to gain a better understanding of how their products, services, or brand are perceived by the public. This information can guide marketing strategies, product improvements, and customer engagement efforts.
Real-time Monitoring: Sentiment analysis on social media enables real-time monitoring of public sentiment during events, product launches, or crises. This rapid feedback can help organizations adapt quickly to changing situations.
Customer Experience Enhancement: By recognizing customer emotions and sentiments, businesses can tailor their interactions and services to enhance customer satisfaction. This personalization can lead to improved customer experiences.
Political and Social Analysis: Sentiment analysis can be applied to gauge public sentiment on political issues, social causes, and events. This can be especially valuable for policymakers and researchers studying societal trends.
Early Warning Systems: Emotion recognition can be employed to detect signs of distress, depression, or other mental health issues in social media posts, potentially allowing for early intervention and support to that person and take it out from that .
Content Moderation and Safety: Sentiment analysis can aid in identifying offensive, harmful, or abusive content on social media platforms, contributing to safer online environments.
Q) Aim(s) and objectives of the proposed project. State two-four objectives of the project and explain how the stated aim(s) can be achieved
Aim: The aim of the proposed project is to develop an effective sentiment analysis and emotion recognition system for social media content.
Objectives:
Build a Labeled Dataset: Collect and curate a diverse and representative dataset of social media posts or comments, manually labeled with sentiment and emotion categories. This dataset will serve as the foundation for training and evaluating the sentiment analysis and emotion recognition models. We need to invest time & manual human effort to collect data.
Implement NLP Techniques: Apply natural language processing (NLP) techniques to preprocess and vectorize the textual data. This involves tasks such as tokenization, removing stop words, stemming, and converting text into numerical representations suitable for machine learning algorithms. We ensures that the models can extract relevant features and patterns from the text. As machine only understand number’s we need to convert that data into vectors
Develop Sentiment Analysis Model: Train a sentiment analysis model using machine learning or deep learning approaches. Experiment with various algorithms and architectures, such as Naïve Bayes, Support Vector Machines, or Recurrent Neural Networks, to accurately classify social media posts into positive, negative, or neutral sentiment categories.
Create Emotion Recognition Model: Design an emotion recognition model using state-of-the-art deep learning architectures, such as Convolutional Neural Networks (CNNs) or Transformer models. Train the model to recognize a range of emotions like happiness, anger, sadness, and more within social media content.
Evaluate and Fine-Tune Models: Assess the performance of both the sentiment analysis and emotion recognition models using appropriate evaluation metrics like accuracy, precision, recall, and F1-score. Fine-tune the models based on evaluation results to improve their accuracy and generalization capability.
Q) Stakeholders: who will benefit from project outcomes?

Businesses and Brands: Organizations can leverage the sentiment analysis outcomes to gauge how their products, services, and brand are perceived by the public. They can tailor their marketing strategies and customer engagement efforts based on the sentiment expressed by customers on social media platforms.
Marketing and Public Relations Professionals: Marketing teams can use the sentiment analysis results to fine-tune their campaigns, respond to customer feedback more effectively, and make data-driven decisions regarding branding and messaging.
Social Media Platforms: Social media platforms can use the insights from the project to enhance their algorithms, improve content recommendations, and create safer online environments by identifying and moderating harmful or abusive content more efficiently.
Psychologists and Mental Health Professionals: The emotion recognition outcomes can have implications for mental health professionals who may use the technology to detect signs of distress or emotional well-being in individuals' online expressions.
Q) Related works. What has been done in this area? What are gaps or shortcomings of the previous works?

Traditional Machine Learning Methods: Earlier studies often used traditional machine learning algorithms like Naïve Bayes, Support Vector Machines, and decision trees for sentiment analysis. These methods relied heavily on handcrafted features and lacked the ability to capture complex linguistic nuances.
Lexicon-Based Approaches: Lexicon-based methods utilized sentiment dictionaries and predefined lists of words with associated sentiment scores. These approaches suffered from limited coverage of informal language and context-specific expressions.
Supervised Learning with Text Classification: Many studies employed supervised learning techniques for sentiment analysis, using labeled datasets to train models. Commonly used classifiers included logistic regression, random forests, and k-nearest neighbours.
Deep Learning Models: More recent works have embraced deep learning techniques, particularly Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and more advanced architectures like Transformers. These models showed improved performance in capturing context and semantics.
Gaps :
Domain Adaptation: Many sentiment analysis models struggled to generalize across different domains, as language and expressions vary between topics and contexts. Fine-tuning models for specific domains remained a challenge.
Negation and Context Handling: Traditional approaches struggled with negations, sarcasm, and context-dependent sentiments, as they heavily relied on individual words without considering their surrounding context.
Data Imbalance and Biases: Datasets used for training often suffered from class imbalance, leading to biased model predictions. Moreover, models could inherit biases present in the training data, affecting fairness and accuracy.
Ethical and Privacy Concerns: Many works overlooked the ethical implications of sentiment analysis, such as user privacy and potential consequences of incorrect sentiment labeling.
Multilingual and Multimodal Analysis: Existing studies primarily focused on English text. The analysis of sentiments and emotions in multiple languages and incorporating other modalities like images and videos were relatively less explored.
Real-Time Processing: Most studies focused on batch processing, and the ability to perform sentiment analysis and emotion recognition in real-time, especially for time-sensitive applications, remained a challenge.
Combining Sentiment and Emotion: Few works integrated sentiment and emotion analysis seamlessly, even though both aspects often play crucial roles in understanding textual content comprehensively.
Q) Data. What dataset(s) will be used to achieve the stated aim(s)? Describe those datasets. How will they be obtained? Are the datasets of sufficient quality? How will be that checked?
Publicly Available Datasets: There are several existing datasets for sentiment analysis and emotion recognition, such as the Sentiment140 dataset, EmoReact dataset, and Movie Review dataset. These datasets often cover a range of sentiments and emotions.
Specialized Datasets: Some datasets are curated for specific domains, like product reviews, political discourse, or mental health-related content. Choose datasets that match your intended application. ( e.g., Kaggle )
Dataset Acquisition:
Permission: Ensure that the datasets you choose are publicly available or can be used for research purposes.
Download: Download the datasets from reputable sources or platforms. Make sure to keep track of the source and any associated metadata.
Preprocessing: Preprocess the data to clean and structure it. This might involve removing duplicates, handling special characters, and converting text to a consistent format.
Assessing Dataset Quality:
Label Quality: Check the accuracy of sentiment or emotion labels. Manually inspect a subset of the data to verify if the labels align with the content.
Data Distribution: Ensure that the dataset represents a diverse range of sentiments and emotions. An imbalanced dataset might bias your model's performance.
Data Completeness: Verify that the dataset contains a sufficient number of instances for each sentiment or emotion category to avoid skewed results.
Contextual Relevance: Ensure that the data is relevant to your target application. Social media language and expressions can vary widely, so relevance is key.
Data Source: Consider the source of the data. Social media platforms evolve, and data from outdated sources might not reflect current trends or language.
Q) Methods. What methods will be employed to achieve the aims of the proposed project? How will you analyse the data? Explain why those methods are suitable for the project?
1. Preprocessing and Text Vectorization:
- Use natural language processing (NLP) techniques to preprocess the raw text data. This involves tokenization, removing stop words, stemming, and handling special characters.
- Employ word embedding techniques like Word2Vec or GloVe to convert text into numerical representations suitable for machine learning models.
2. Supervised Learning for Sentiment Analysis:
- Train supervised learning models like Logistic Regression, Support Vector Machines, or neural networks to classify social media posts into sentiment categories (positive, negative, neutral).
- Use the labeled dataset to train and validate the models, optimizing hyperparameters for better performance.
3. Deep Learning for Emotion Recognition:
- Employ deep learning architectures like Convolutional Neural Networks (CNNs) or Transformer-based models to perform emotion recognition.
- Train the model on a dataset with labeled emotions (e.g., happy, sad, anger) to learn representations that capture nuanced emotional content in text.
4. Transfer Learning using Pre-trained Models:
- Fine-tune pre-trained language models (e.g., BERT, GPT) on the sentiment analysis and emotion recognition tasks.
- Adapt the models to the specific domain of social media language and emotions.
5. Evaluation and Metrics:
- Evaluate the sentiment analysis model using metrics like accuracy, precision, recall, and F1-score. Assess the model's ability to correctly classify sentiments in the dataset.
- For emotion recognition, employ similar evaluation metrics to assess the model's performance in categorizing different emotions.
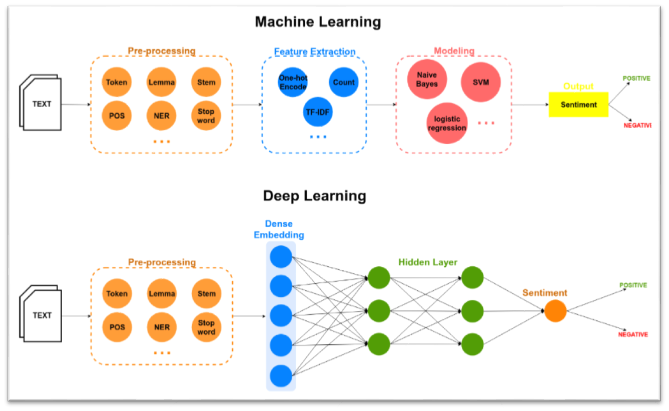
Analysis Rationale:
- Preprocessing and Text Vectorization: These methods are essential to convert raw text data into a format that machine learning models can work with. They ensure that linguistic nuances, context, and features are appropriately captured.
- Supervised Learning for Sentiment Analysis: As you have labeled data for sentiment analysis, supervised learning methods allow you to learn patterns from the data and classify sentiments
- Deep Learning for Emotion Recognition: Emotion recognition involves understanding subtle contextual cues and nuances in language. Deep learning models, particularly CNNs and Transformers, have shown superior performance in capturing such complexities.
- Transfer Learning using Pre-trained Models: Transfer learning takes advantage of the pre-trained models' extensive language understanding, reducing the need for large annotated datasets and enhancing model performance.
- Evaluation and Metrics: Rigorous evaluation using standard metrics provides a quantifiable measure of your models' performance, enabling you to compare different approaches and select the best-performing one.
Q) Work plan. What are the key steps of the proposed project? How long each step may take? What are key milestones for the evaluation of the progress on the project
1. Project Initialization (1 week):
- Define project scope, objectives, and research questions.
- Review related literature and identify gaps.
2. Data Collection and Preprocessing (2 weeks):
- Identify and select suitable datasets for sentiment analysis and emotion recognition.
- Obtain necessary permissions for data usage.
- Download and preprocess data, including text cleaning and tokenization.
3. Exploratory Data Analysis (1 week):
- Visualize dataset characteristics, such as distribution of sentiments and emotions.
- Identify potential issues like data imbalance or biases.
4. Text Vectorization and Feature Engineering (2 weeks):
- Implement NLP techniques for text vectorization, such as word embedding.
- Experiment with different text representation methods to find the most suitable one.
5. Sentiment Analysis Model Development (3 weeks):
- Train and evaluate initial sentiment analysis models using supervised learning approaches.
- Tune hyperparameters to improve model performance.
6. Emotion Recognition Model Development (4 weeks):
- Implement deep learning architectures for emotion recognition, using pre-trained embeddings
- Train models on labeled emotion datasets and fine-tune hyperparameters.
- Evaluate and compare model performance using appropriate metrics.
7. Transfer Learning and Model Fine-tuning (2 weeks):
- Experiment with fine-tuning pre-trained language models for sentiment analysis & emotion recognition.
8. Model Evaluation and Optimization (3 weeks):
- Evaluate sentiment analysis and emotion recognition models on validation data.
- Optimize models based on evaluation results, addressing any overfitting or underperformance issues.
9. Ethical Considerations and Bias Analysis (2 weeks):
- Analyze models for potential biases and ethical concerns.
- Implement strategies to mitigate biases and ensure fair predictions.
10. Documentation and Report Writing (3 weeks):
- Document the entire process, including data preprocessing, model development & evaluation.
Key Milestones:
Literature Review and Research Questions Finalized
Datasets Collected and Pre-processed
Exploratory Data Analysis Completed
Initial Sentiment Analysis Models Developed and Evaluated
Emotion Recognition Models Trained and Evaluated
Transfer Learning and Model Fine-tuning Completed
Model Evaluation and Optimization Finished
Ethical Considerations Addressed and Bias Analysis Conducted
Project Documentation and Report Writing Concluded
Q) Risk assessment. What can go wrong? How will you mitigate those risks? List 3-5 project related risks
Risk 1: Data Quality Issues
What Can Go Wrong: The collected or curated datasets might have inconsistencies, errors, or biases that affect the quality of model training and evaluation.
- Perform thorough data preprocessing to clean and standardize the data.
- Conduct exploratory data analysis to identify and address data quality issues.
- Use data augmentation techniques to generate synthetic samples for addressing data imbalance.
Risk 2: Model Overfitting
What Can Go Wrong: The developed sentiment analysis and emotion recognition models might perform well on the training data but fail to generalize to new, unseen data.
- Implement techniques like cross-validation to evaluate models on multiple folds of the data.
- Regularize models using techniques like dropout or L2 regularization to prevent overfitting.
- Consider ensemble methods that combine multiple models to improve generalization.
Risk 3: Ethical and Bias Concerns
What Can Go Wrong: The models might inadvertently reinforce biases present in the training data, leading to unfair or biased predictions. Additionally, the deployment of the models might raise ethical concerns related to user privacy.
- Analyze the training data for biases and take corrective actions, such as re-sampling or using debiasing techniques.
- Implement fairness-aware algorithms to mitigate bias during model training.
Risk 4: Resource and Time Constraints
What Can Go Wrong: Insufficient resources (computational power, human resources, etc.) or time constraints might impact the thoroughness of model training, evaluation, and documentation.
- Allocate sufficient time for each project phase in the work plan to prevent rushed implementations.
- Prioritize tasks and focus on the most critical aspects of the project.
Q) Expected results. Describe what the project is likely to output, what conclusions could be made? Can these results be generalised? If yes, then how and to what degree?
Expected Outputs:
1. Trained Models: You will have sentiment analysis and emotion recognition models that can classify social media content into sentiment categories (positive, negative, neutral) and recognize various emotions (happiness, anger, sadness, etc.).
2. Evaluation Metrics: Metrics such as accuracy, precision, recall, and F1-score will quantify the performance of your models.
3. Documentation and Report: A comprehensive project report detailing the methodology, findings, challenges, and recommendations. This documentation will serve as a valuable resource for future projects and research.
Generalization:
1. Data Representativeness: If the selected datasets are diverse and representative of a wide range of social media content, the models' results are more likely to generalize well to similar contexts.
2. Domain Specificity: The more closely your datasets mirror the target application's domain, the more applicable your models will be to similar situations.
3. Model Robustness: Models that perform well on validation and test data and demonstrate resilience to variations in the input data are more likely to generalize.
4. Bias Mitigation: Effective bias mitigation techniques and ethical considerations can enhance the generalizability of the models across diverse user groups.
5. Transfer Learning: If transfer learning is employed and fine-tuned models show good performance, the models' capabilities might be transferable to other related domains.
Q) Evaluation. How will you evaluate and validate that the results of your project are sound?How will you evaluate if the aims of the project have been achieved?
Evaluation of Results:
Model Performance Metrics: Employ a variety of evaluation metrics such as accuracy, precision, recall, F1-score, and possibly ROC curves or AUC to assess the performance of both the sentiment analysis and emotion recognition models.
Cross-Validation: Use techniques like k-fold cross-validation to evaluate your models on multiple subsets of the data. This helps you assess their generalization ability and robustness.
Hyperparameter Tuning: Evaluate the impact of different hyperparameter choices on model performance. This ensures that your models are optimized and not overfitting.
Comparison to Baselines: Compare your models' performance against baseline models or existing state-of-the-art models for sentiment analysis and emotion recognition. This provides a benchmark for measuring success.
Bias Analysis: Evaluate the effectiveness of bias mitigation techniques by measuring the reduction in biases within your models' predictions.
Validation of Project Aims:
Quantitative Metrics: Use specific quantitative metrics to assess if the project's aims have been achieved. For instance, if your aim is to achieve a certain level of accuracy or F1-score, verify if your models meet these targets.
Qualitative Analysis: Conduct qualitative analysis by manually reviewing a sample of predicted sentiment and emotion labels. This helps confirm whether the models' predictions align with human intuition.
Use Case Scenarios: Validate the models in real-world use case scenarios, such as analyzing sentiment during a major event or emotion recognition in a specific domain. Assess how well the models perform in these practical scenarios.
User Feedback: If applicable, collect user feedback on the accuracy and effectiveness of sentiment and emotion predictions. User perspectives can provide valuable insights into model performance.
Milestone Checkpoints: Regularly compare the achieved results against the key milestones defined in your project plan. This helps ensure that you're on track to achieving the aims you've set.
Q) References. Provide references to related works, methods, your literature review (if relevant), approximately 10-15 references.
Pang, B., & Lee, L. (2008). Opinion mining and sentiment analysis. Foundations and Trends® in Information Retrieval, 2(1-2), 1-135.
Socher, R., Perelygin, A., Wu, J. Y., Chuang, J., Manning, C. D., Ng, A. Y., & Potts, C. (2013). Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing
Haddi, E., Soufiane, B., & Abdelhak, M. (2013). Arabizi detection: A sentiment analysis approach. Journal of King Saud University-Computer and Information Sciences, 25(3), 267-278.
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
Agarwal, A., Xie, B., Vovsha, I., Rambow, O., & Passonneau, R. (2011). Sentiment analysis of Twitter data. In Proceedings of the workshop on languages in social media.
Wang, P., Xu, J., Xu, B., Liu, C., Zhang, F., Wang, H., ... & Si, L. (2020). Sentiment analysis of Chinese financial news based on LSTM and word embedding. IEEE Access, 8, 36163-36172.
Ekman, P. (1992). An argument for basic emotions. Cognition & Emotion, 6(3-4), 169-200.
Felbo, B., Mislove, A., Søgaard, A., Rahwan, I., & Lehmann, S. (2017). Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion, and sarcasm. In Proceedings of the 2017 conference on empirical methods in natural language processing.
Li, J., & Xu, S. (2019). Emotion recognition in text with stacked bidirectional LSTM and MLP. IEEE Access, 7, 33619-33627.
10. Cambria, E., & Hussain, A. (2012). Sentic computing: A common-sense-based framework for concept-level sentiment analysis. IEEE Transactions on Knowledge and Data Engineering, 24(6), 1203-1218.
To get any help you can send your assignment requirement details at:



link s666 hôm trước mình lướt thử vì thấy mấy đứa bạn hay nhắc, chủ yếu tò mò xem trang họ làm ra sao thôi. Mình không đăng ký hay chơi gì, chỉ đọc qua vài đoạn giới thiệu. Ấn tượng là họ chia nội dung khá dễ theo dõi, kiểu có phần nói về “sân chơi” và thông tin chung nhìn vào là hiểu ngay, không phải mò lâu. Có đoạn nhắc máy chủ đặt ở Philippines nên mình cũng dừng lại đọc vì ít chỗ ghi cụ thể vậy. Kéo xuống mấy khối nội dung trình bày gọn, chữ không bị dày đặc nên lướt nhanh vẫn nắm được ý. Menu đặt ngay phía trên nên bấm qua…
HD88 dạo này thấy bạn bè nhắc hoài nên mình cũng bấm vào coi thử cho biết thôi. Mình không có chơi hay đăng ký gì, chỉ lướt vài phút xem trang nhìn ra sao. Cảm giác đầu tiên là giao diện khá dễ chịu, không bị nhồi nhét, nhìn vô là biết chỗ nào để bấm chuyển mục. Mình thích kiểu họ chia nội dung thành từng khối rõ ràng, chữ không quá nhỏ nên đọc nhanh vẫn ổn. Với lại phần menu để khá nổi, nên dù mới vào cũng không phải tìm lâu mới biết đi đâu. Nói chung lướt qua thấy gọn gàng, các khối thông tin xếp ngay ngắn và menu nằm chỗ dễ thấy…
https://rr88m1.com/ hôm trước mình thấy bạn bè nhắc qua nên bấm vào xem thử cho biết. Mình hay để ý mấy thứ cơ bản thôi như bố cục và cách họ dẫn dắt người mới, chứ không có ngồi “soi” sâu. Vào trang cái thấy giao diện khá dễ nhìn, nền nã, kéo xuống không bị rối vì các khung nội dung chia rõ ràng. Có đoạn họ nói về nguồn gốc/pháp lý và năm thành lập, đọc lướt vẫn hiểu được chứ không kiểu viết mập mờ. Chuyển qua lại giữa các mục cũng ổn, không bị giật lag hay load lâu. Nói chung cảm giác họ sắp xếp thông tin theo từng box gọn gàng, tiêu đề nổi…
socolives.jp.net bữa mình lướt thử vì thấy mấy đứa bạn nói có mục World Cup 2026 nhìn khá rõ. Vào không cần đăng ký gì cũng xem được bố cục tổng quan, kiểu chia nội dung thành từng khối nên kéo xuống là nắm được đang nói gì. Mình để ý họ có nhắc đường truyền “siêu tốc” với chuyện lệch vài giây so với chỗ khác, nghe cũng thú vị nhưng chắc còn tùy mạng nhà mỗi người. Nói chung trang nhìn gọn, chữ dễ đọc, không bị nhồi nhét quá nhiều thứ một lúc. Đặc biệt phần thông tin World Cup 2026 được đặt thành mấy block riêng nên nhìn phát là thấy ngay trên trang.
sunwin dạo này thấy nhiều người nhắc nên mình cũng ghé thử cho biết, kiểu vào xem giao diện ra sao thôi chứ không có ngồi mò kỹ. Vừa mở lên là thấy trang làm khá “dễ thở”, khoảng trắng vừa đủ nên nhìn không bị rối mắt. Mình để ý cái menu đặt khá nổi, bấm qua lại mấy mục thấy phản hồi nhanh, không phải kéo lên kéo xuống tìm chỗ điều hướng. Nội dung thì họ chia theo từng khối riêng, nhìn lướt là biết phần nào với phần nào, đọc nhanh vẫn nắm được ý chính. Nói chung cảm giác thân thiện cho người mới, nhất là cách họ gom thông tin theo block và để…